
Sonic Deep Reinforcement Learning

Project Overview
For my passion project at Metis I wanted to focus on learning about a machine learning paradigm we didn’t cover in the course, reinforcement learning (RL). RL was intriguing to me for a number of reasons. First, I have a background in game development and RL it has gotten a great deal of notoriety lately due to is successes in defeating human players at very complex games such as Go, StarCraft 2, and DOTA 2. I wanted to understand how RL was able to accomplish this. Additionally, I also have deep interest in cognitive science and evolution and the high level approach of RL was developed according to the way in which it is believed that humans and animals interact with the world to achieve their goals. This made learning about RL very hard to pass up.
However, reinforcement learning and the neural network version of the discipline deep reinforcement learning are technically challenging fields that have techniques that are very unique and where training models can be very time intensive. On top of that, implementing RL models for existing games has the additional challenge of creating APIs for them that allow the models to interact with them. That alone could be a weeks long effort, even for a skilled engineer, but fortunately OpenAI has famously created a framework for testing RL models on a broad assortment of classic games called OpenAI Gym. In addition, the Gym API also provides baselines for successful RL models, allowing users to more easily implement them and try their own approaches with the games available in Gym.
OpenAI’s main collection of games focuses on Atari 2600 titles, but an add-on to the API called Retro Gym adds many other emulated consoles and games into the Gym ecosystem, raising the number of games to over 1000. With these tools I was confident I could get an RL model up and running in the time we had for the project.
Reinforcement learning was still going to be a challenging paradigm to learn though and my main goal was to gain insight and expertise in the field, so I approached this primarily as a research project where I would be learning how RL through successful established models and approaches. I wanted to come away with a solid conceptual understanding of RL as well as good overview of the more effective models and underlying algorithms that applied to games.
I started out keeping my options open in terms of the game to focus on for the final modeling. OpenAI Gym and Retro had a wide assortment of candidates that were interesting. I wanted to avoid the simplistic baseline environments (Cartpole, FrozenLake, Taxi) as they’re not very exciting and largely solved problems and the Lunar Lander, while fun, had been done before at Metis and was a fairly simple system, even though the state space was continuous, which is trickier than discrete state spaces.
I was looking at some classic Atari games like Space Invaders and Kung-Fu, when I came across a very helpful deep reinforcement learning tutorial that focused on more interesting games like Doom and Sonic the Hedgehog. Sonic was a favorite of mine from the classic Genesis days, so even though I didn’t fully understand the approaches or models involved yet, the existence of a tutorial using Sonic as an example convinced me I could get it up and running in time, soI decided to focus on the first Sonic the Hedgehog game for the final project, using the tutorial as a roadmap.
For the purposes of the model and having a problem to solve as a driving force for the work I wanted to answer the question “Can we teach an AI agent to complete the first level of the first Sonic the Hedgehog game?”
Visit the Github repo to see the data, code and notebooks used in the project.
##References My research was extensive so to summarize I’ll list the most useful/influential sources here:
- Playing Atari with Deep Reinforcement Learning - This is the paper describing Google DeepMind’s efforts with using Deep Reinforcement Learning to teach AI agents to play classic Atari games at or exceeding human levels of skill. This is widely-regarded as the effort that really legitimized DRL as an effective approach to solving complex systems and DRL efforts with games after this largely can be traced back to this. It introduces Deep Q-Learning , the precursor to many more advanced DRL techniques.
- Explained Simply: How DeepMind taught AI to play video games - Provided deeper understanding and explanations for the Atari paper above.
- Free Deep Reinforcement Learning Course - The course mentioned above that I used as a primary roadmap for my RL research and modeling. It moves through increasingly complex RL models and techniques and was a superb guide and reference.
- Simple Reinforcement Learning with Tensorflow - Another excellent tutorial series on reinforcement learning and its implementation in Tensorflow.
- Deep Reinforcement Learning Hands On - My other primary reference and tutorial for DRL on this project. When the free tutorial wasn’t providing results or depth of explanation I needed to get a full grasp of the space I sought out a more in-depth examination and this book ended up being an excellent reference, both for theory and actual implementation.
- Sonic the Hedgehog Retro Contest - Another reason why Sonic seemed like a very solvable problem space was because OpenAI had actually run a contest to challenge the public to come up with the most effective Sonic model. Exploration of these techniques was a rich research space and ended up providing the most definitive approaches to the modeling problem.
- Gotta Learn Fast: A New Benchmark for Generalization in RL - In this paper OpenAI lays out the foundation for the baseline model approaches to solve for an effective Sonic model. This was published before the contest and the contestants largely used variations of the described baselines to get the best results.
- Alexadre Borghi’s PPO Variant - When the tutorial model approaches weren’t getting great results I went straight to the source of the successful models that worked for the sonic contest. Alexandre Borghi placed 3rd and provided his model for others to experiment with. There were a few adaptations to make it work on my system and also to just focus on the first level, but the final successful model is primarily this one.
##Methodology
- Use established reinforcement learning models to build a model that can complete the first level of Sonic the Hedgehog.
##Data
- As is typical with reinforcement learning models data to be used for training the model is generated through agent interaction with the game environment. It’s not uncommon to bootstrap RL models with a pre-trained model or high level human player episodes, but in this case it wasn’t necessary.
Tools
- Python
- PyTorch
- Tensorflow
- Amazon Web Services (AWS)
- OpenAI Gym
- OpenAI Retro-Gym
- Pandas
- Numpy
- Seaborn
- Matplotlib
Modeling
Deep Reinforcement Learning with Sonic
The two primary modeling techniques used to try to solve for Sonic were Advantage Actor-Critic (A2C) and Proximal Policy Optimization (PPO), which is a variation on A2C that effectively regularizes the policy that the agent uses to decide what to do in a given state.
To briefly explain Advantage Actor-Critic, it is a policy-based model, as opposed to a value-based model that attempts to learn the best policy to decide what action to take in a given state without explicitly taking the value of that action in that state into account. It takes a probability distribution over all possible actions and random rolls the action at each step according to the distribution. Actions that tend to generate better rewards will tend to get picked more often, but there is always a possibility that a different action will get chosen at every step. This is good as it introduces randomness to ‘attempt’ to prevent the model from overfitting or optimizing to a bad state. As it turns out overfitting can still happen though.
Other important aspects of the A2C approach are the Actor-Critic portion where two models are running in tandem. One is the Actor that chooses actions based upon the policy-based approach mentioned above, and the other model is the Critic that makes a value-based evaluation of that action to gauge its worth and updates the Actor with that evaluation so it can take better actions in the future.
Finally the “Advantage” aspect of the model, instead of looking at the absolute value of the current policy decision and using that to evaluate how good it is, it looks at the difference between the current decision and the previous decision made in the same state. It is looking at the advantage the current decision has over the previous one.
Note that the above is a rather simplified explanation of how A2C works. There are many more details that can provide deeper insight.
The variation on A2C used in the tutorial got Sonic past some initial obstacles in the level, but had a very hard time dealing with the loop mechanic in the game:
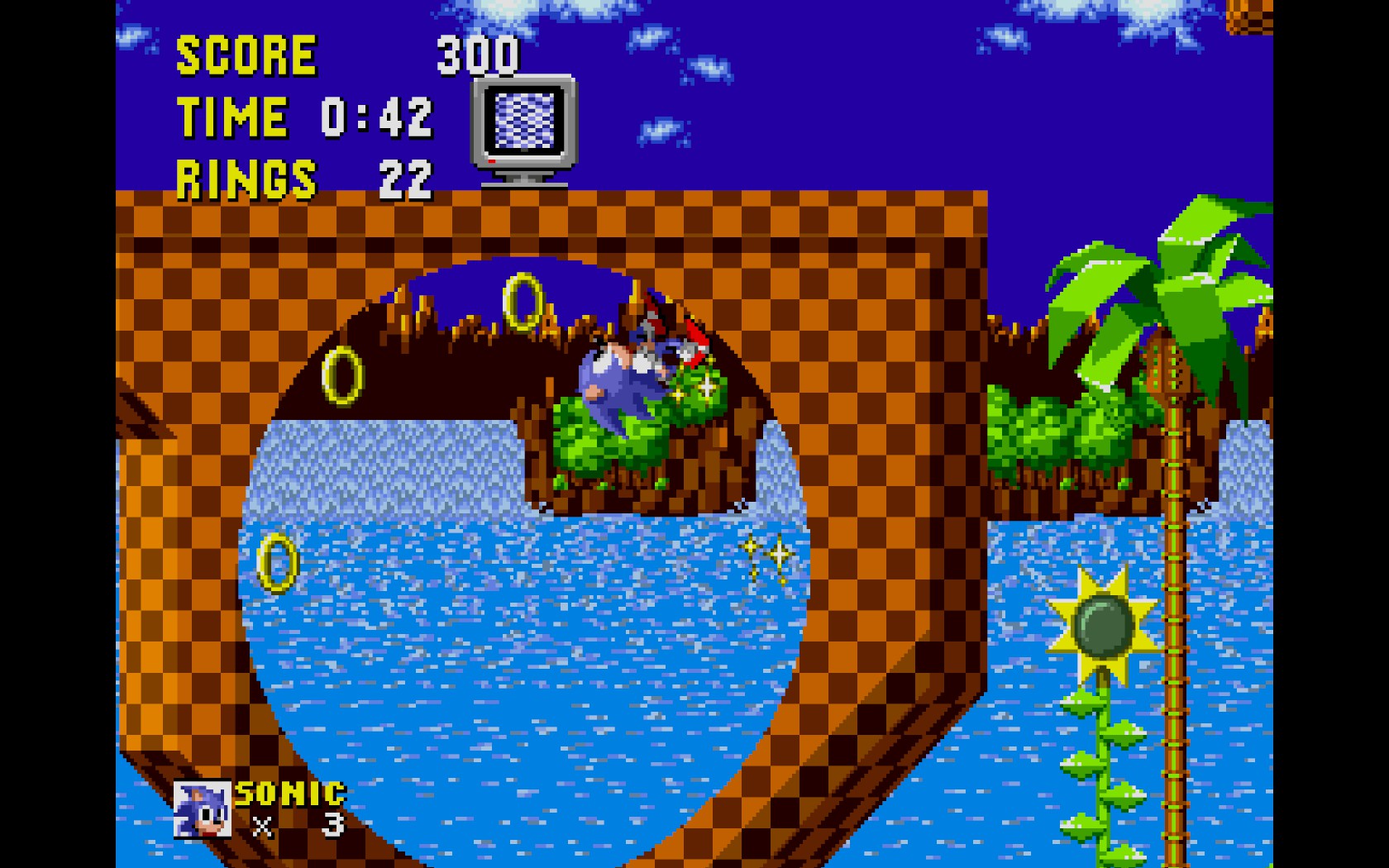
Loops, backtracking, verticality, tunneling and other non-standard forms of progression are signatures of the Sonic games and distinguish them from other platformer-type games of the era like the Mario games and because they are unconventional they can be tricky for an uncalibrated model to figure out, even one with a deep neural network at work on it.
Additional longer training of the A2C model didn’t improve things and actually made them worse, as it seemed that model has a tendency to overfit over longer training sessions. In this case the model learned to just run to the left and not attempt to move right to get to the end of the level at all:

At this point it was time to move on to a different approach so I moved on to the Proximal Policy Optimization model in the tutorial. PPO is essentially A2C, but with a regularization applied to the policy decision. It will only allow policy variations within a certain numerical range and anything outside of that gets clipped to that range. This should in theory work to additionally prevent overfitting or wild oscillations in the actions being taken.
However, unfortunately PPO didn’t provide significantly improved results. It still got stuck on the loop or couldn’t figure out how to deal with the tricky field of spikes later in the level and this is even after over 10 hours of training. It simply didn’t improve.
In deep reinforcement learning there are many different parameters to potentially tweak to try to improve performance, but they are so numerous that random guessing, at one end, and a methodical grid search, at the other, are both impractical, both due to the number of parameters available, and the training time. Neural networks can take a long time to train so that puts a practical cap on any randomized parameter search, outside maybe of a major corporation like Google.
As such, a small team or individual has to rely on domain expertise to direct the agent in better directions and this is what I felt was necessary for the Sonic model. Random actions with no weighting was not really working out so I felt we needed to incentivize to Sonic to try actions that are better for the Sonic game specifically. Things like running for extended periods and running then ducking to do a spin dash are specific to Sonic so they should be incentivized.
In looking at the contest entrants it seemed like Alexandre Borghi’s model had solved for these specific problems and because the tutorial code was largely based on his approach this seemed like the best option for getting something up and running in time.
Once I got it running I split the training in two with a model training on the first level alone running on my laptop and a more robust approach training on all levels in the game running on AWS.
It took some time to adapt the code to my setup and to have it focus just on the first level of the game, but after getting it up and running and training overnight for around 12 hours it produced pretty spectacular results. For the model running on my laptop Sonic was able to deal with the first level in an exceedingly skillful way. By about the 3000th iteration of the model Sonic was able to get through the first level in about 45 seconds, which is a really fast and efficient time. Whenever he would get stuck he would quickly apply a method that got him past the obstacle and got him to the end of the level:
!
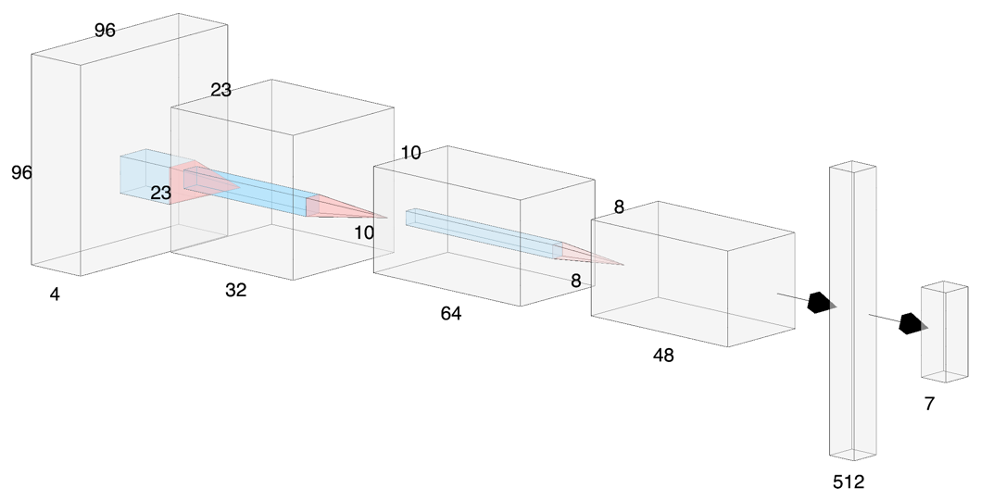
I’ll briefly lay out neural network in the final model flow:
- Input: 4 preprocessed frames scaled down to 96x96 and grayscaled
- Convolution 1: Filters: 32, CNN Kernel: 8x8, Stride: 4
- ReLU Activation
- Convolution 2: Filters: 64, CNN Kernel: 4x4, Stride: 2
- ReLU Activation
- Convolution 3: Filters: 48, CNN Kernel: 3x3, Stride: 1
- Fully Connected Layer 1: 512
- Fully Connected Layer 2: 7
- This final FC layer will output one of the seven possible actions for the agent to take.
Ultimately the Borghi model was extremely effective and solved for the deficiencies with the baseline PPO model and I would like to continue to dig into to fully understand all aspects of it so I can implement my own variation that can hopefully apply to other games.
Future Work
- Generalized Sonic 1 Model: Continue working with this model to see if we can get to generalize well to the entire Sonic 1 game.
- Sonic X: Attempt to apply the model that generalizes well on Sonic 1 to games later in the series to see how well it generalize to “playing Sonic” regardless of the title.
- Street Fighter Combo Master: As a much more ambitious long-term DRL project I’d like to create an agent that can create effective combos in Street Fighter games. Combos in these games become optimized sequences that are required to get maximum damage with each opening the opponent exposes to you. If you can’t combo with complete consistency and efficiency you simply won’t do as well as others who can. Creating an agent that can learn to combo with high efficiency in every scenario would be an important step towards creating an overall solid AI agent for Street Fighter, and fighting games in general, that is both very good and also plays like a skilled person.
Resources
-
Github Repository - GitHub repository containing code, presentations and data.
-
Presentation Deck - This is a PowerPoint presentation deck created for a live presentation of project results.